Auto MC-Reward: Automated Dense Reward Design with Large Language Models for Minecraft
Abstract
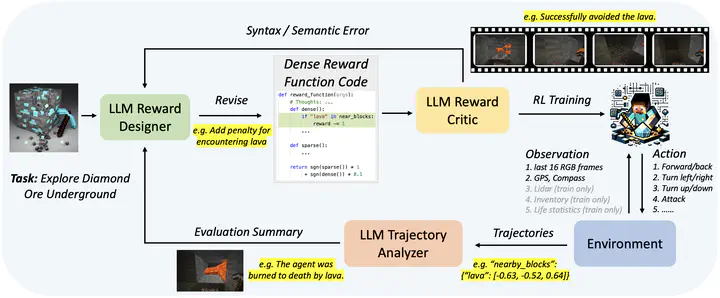
Traditional reinforcement-learning-based agents rely on sparse rewards that often only use binary values to indicate task completion or failure. The challenge in exploration efficiency makes it difficult to effectively learn complex tasks in Minecraft. To address this, this paper introduces an advanced learning system, named Auto MC-Reward, that leverages Large Language Models (LLMs) to automatically design dense reward functions, thereby enhancing the learning efficiency. Auto MC-Reward consists of three important components: Reward Designer, Reward Critic, and Trajectory Analyzer. Given the environment information and task descriptions, the Reward Designer first design the reward function by coding an executable Python function with predefined observation inputs. Then, our Reward Critic will be responsible for verifying the code, checking whether the code is self-consistent and free of syntax and semantic errors. Further, the Trajectory Analyzer summarizes possible failure causes and provides refinement suggestions according to collected trajectories. In the next round, Reward Designer will take further refine and iterate the dense reward function based on feedback. Experiments demonstrate a significant improvement in the success rate and learning efficiency of our agents in complex tasks in Minecraft, such as obtaining diamond with the efficient ability to avoid lava, and efficiently explore trees and animals that are sparse on the plains biome.